Bila bicara soal load testing, yang terbayang dalam kepala saya adalah Apache JMeter. Namun kali ini saya akan mencoba sebuah tool baru yang disebut Locust. Salah satu perbedaan utamanya adalah definisi tugas pengujian JMeter dilakukan melalui UI sementara definisi pengujian Locust ditulis melalui kode program Python. Mana yang sebenarnya lebih mudah dan intuitif? Secara logika, seharusnya JMeter, bukan? Tapi entah mengapa saya merasa banyak yang butuh waktu untuk mempelajari UI JMeter sebelum bisa mulai bekerja dengannya. Sementara itu, karena skenario Locust adalah kode program Python, pembuat skenario bisa copy paste dan menerapkan teknik pemograman yang sudah biasa mereka pakai.
Untuk memakai Locust, saya menambahkannya dengan menggunakan pip di proyek Python saya seperti pada perintah berikut ini:
$
pip install locust
Karena ini adalah kode program biasa, saya juga bisa menambahkan library lain, misalnya saya akan memakai faker untuk menghasilkan teks acak:
$
pip install faker
Setelah itu, saya membuat sebuah file dengan nama locustfile.py dengan isi seperti berikut ini:
import faker
from locust import HttpUser, task, between
fake = faker.Faker()
class InventoryUser(HttpUser):
host = 'https://api.latihan.jocki.me'
access_token = None
wait_time = between(1, 5)
def on_start(self):
response = self.client.post(
'https://auth.latihan.jocki.me/auth/realms/latihan/protocol/openid-connect/token',
headers={
'Authorization': 'Basic bG9jdXN0OjRmNzAzNzY0LTllYjItNGUxYS1iM2QyLWY2YmVhMTY0NTIwMw==',
'Content-Type': 'application/x-www-form-urlencoded'
},
data={
'grant_type': 'urn:ietf:params:oauth:grant-type:uma-ticket',
'audience': 'locust',
}
)
self.access_token = response.json()['access_token']
@task
def create_item(self):
self.client.post(
'/stock-item-service/items',
headers={
'Authorization': 'Bearer ' + self.access_token
},
json={
"sku": fake.bothify(text="???-#####"),
"name": fake.name(),
"quantity": fake.random_int(),
"category": fake.random_element(('CPU', 'Memory', 'Storage', 'Motherboard', 'GPU'))
}
)
Kode program di atas mewakili apa yang akan dilakukan oleh seorang User. Locust akan mengerjakan method on_start() pada saat User dibuat dan on_stop() pada saat User di-hentikan (misalnya saat pengguna men-klik tombol Stop). Untuk memanggil API di https://api.latihan.jocki.me, pengguna perlu login terlebih dahulu. Untuk mempermudah proses login, saya menggunakan metode Client Credentials Flow yang cocok untuk komunikasi antar service (machine to machine).
Untuk itu, saya membuat sebuah client baru di Keycloak dengan nama locust, mengisi nilai “Access Type” dengan confidential dan mengaktifkan Authorization Enabled (serta mematikan Standard Flow Enabled). Karena tidak ingin menangani token yang kadaluarsa, saya mengisi mengisi Access Token Lifespan (di bagian Advanced Settings) dengan nilai yang besar seperti 5 jam. Dengan demikian, saya tidak akan mengalami masalah dengan token selama melakukan pengujian tidak lebih dari 5 jam. Saya bisa mendapatkan nilai Client Secret di bagian Secret di tab Credentials. Saya kemudian menyertakan nilai kombinasi client id dan client secret seperti locust:12345678 dalam bentuk base64 encoded di header Authorization di kode program on_start. Keycloak kemudian akan mengembalikan sebuah JSON yang berisi property access_token yang dapat saya pakai saat memanggil API.
Bila menggunakan kcadm.sh, saya bisa memberikan perintah berikut ini:
$
kcadm.sh create clients -r latihan -s clientId=locust -s enabled=true \
-s serviceAccountsEnabled=true -s authorizationServicesEnabled=true -s standardFlowEnabled=false \
-s clientAuthenticatorType=client-secret -s secret=12345678 -s 'attributes={"access.token.lifespan":18000}' \
--no-config --server https://auth.latihan.jocki.me/auth --user user --password password --realm master
Client Credentials Flow menggunakan client id dan client secret yang hampir sama seperti username dan password di Basic Authentication. Lalu apa bedanya? Pada Basic Authentication, username dan password harus selalu dilewatkan saat memanggil API. Bila berhasil disadap, mereka bisa dipakai kapan saja selama belum diganti. Sementara itu, pada Client Credentials Flow, client id dan client secret hanya perlu dilewatkan sekali saja untuk mendapatkan sebuah access token. Selanjutnya, saat memanggil API, access token ini yang akan dipakai. Access token memiliki masa hidup yang singkat seperti 5 menit dan selanjutnya perlu diperbaharui melalui refresh token. Penyadap hanya bisa mendapatkan access token dengan menyadap komunikasi di server API; itupun tidak akan bisa digunakan lagi setelah kadaluarsa.
Dengan meningkatkan masa kadaluarsa access token menjadi 5 jam, saya sudah meningkatkan resiko bila terjadi serangan. Akan tetapi, sebagai gantinya, kode program pengujian lebih mudah. Lagi pula, client id ini tidak akan dipakai oleh server lain.
Sebagai perbandingan, untuk mencapai hal yang sama di JMeter, saya perlu menambahkan konfigurasi HTTP Request untuk memanggil Keycloak, HTTP Header Manager untuk menyertakan client id dan client secret, JSON Extractor untuk mengambil nilai access token yang dikembalikan dan BeanShell Assertion untuk menyimpan access token agar bisa dipakai oeh HTTP Request lainnya, seperti yang diperlihatkan oleh gambar berikut ini:
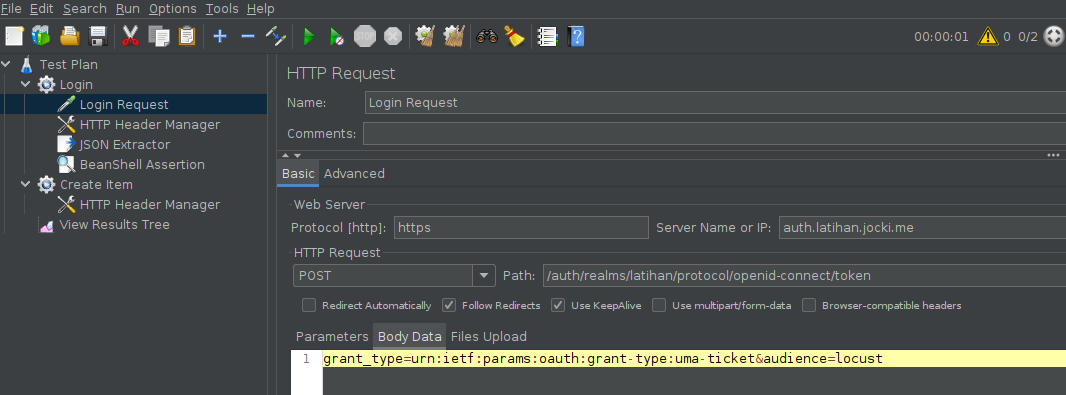
Mereka yang baru mengenal JMeter mungkin akan bingung memilih apa yang harus dipakai untuk mengambil nilai JSON (jawabannya: JSON Extractor), sementara mereka yang membaca kode program Python self.access_token = response.json()['access_token'] biasanya langsung mengerti kalo baris ini akan menyimpan nilai ke variabel. Terkadang UI justru membingungkan karena penggunanya harus memahami terminologi yang dipakai (misalnya apa itu JSON Extractor dan BeanShell Assertion) serta membaca dokumentasi untuk mengetahui apa yang harus di-isi di sekian banyak input yang tersedia.
Pada saat saya menjalankan Locust, method yang memiliki annotation @task seperti create_item() akan terus dikerjakan berulang kali untuk User bersangkutan hingga saya mematikan Locust. Sebagai contoh, saya bisa menjalankan pengujian dengan memberikan perintah berikut ini:
$
locust
Locust akan membaca skenario yang saya tulis di locustfile.py dan menuliskan sebuah link untuk membuka web interface-nya. Sebelum pengujian dimulai, saya dapat menentukan jumlah user, seberapa banyak user baru di buat setiap detiknya serta lokasi server. Saya kemudian men-klik tombol Start swarming untuk memulai pengujian. Pengujian akan terus berlangsung hingga saya meng-klik tombol Stop. Hasil yang saya peroleh terlihat seperti pada gambar berikut ini:
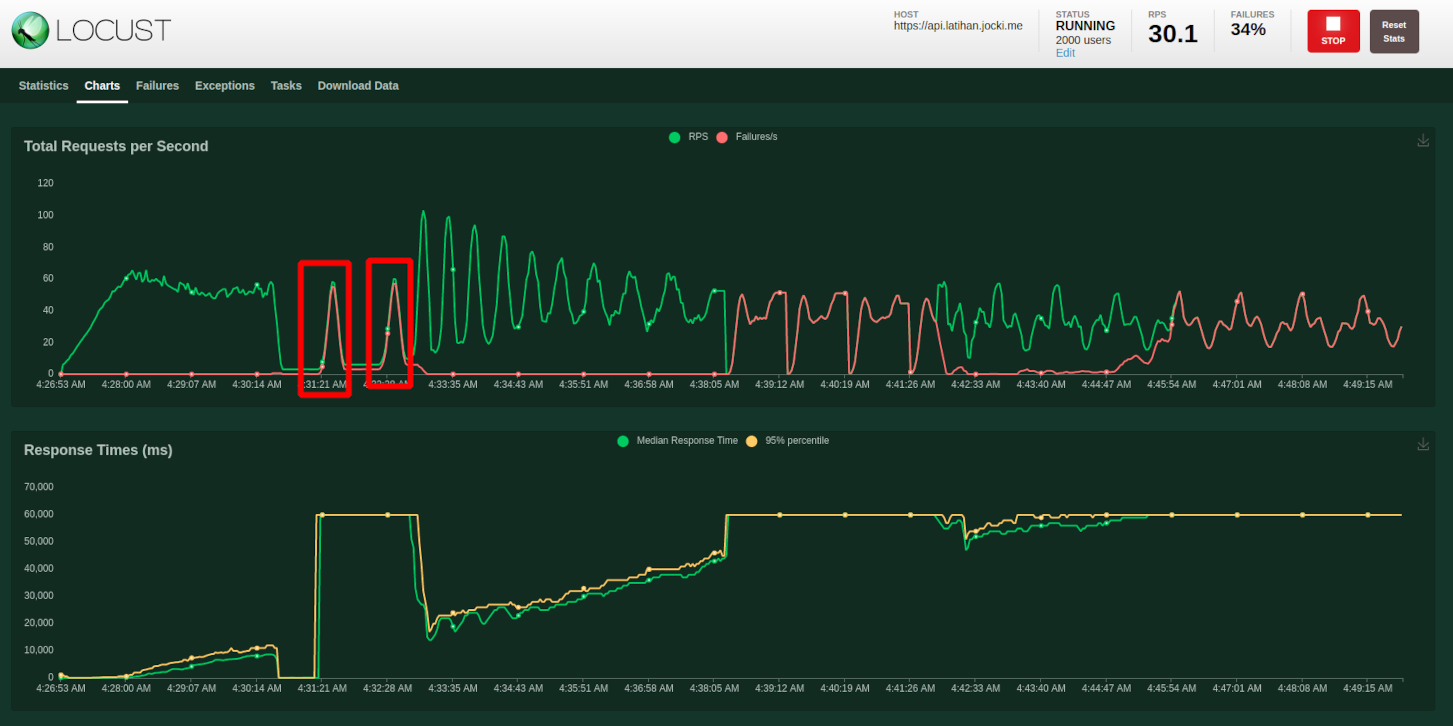
Terlihat bahwa pada awalnya aplikasi ini memiliki kecepatan yang stabil. Namun saat dipaksakan lebih lanjut, pod RabbitMQ dan MongoDB akan berubah ke status unhealthy. Kubernetes-pun akan me-restart pod yang tidak responsif. Namun karena saya hanya memakai sebuah pod tunggal, pengguna akan mendapatkan respon kesalahan saat proses restart terjadi. Pada akhir dari grafis, banyak pesan kesalahan dari ingress controller dengan kesalahan 504 Gateway Time-out. Ini mungkin terjadi karena saturasi jaringan yang tinggi mengingat saya melakukan pengujian di komputer yang sama. Untuk hasil yang sempurna, Locust harus dijalankan pada cluster berbeda sambil melakukan pemantauan pada penggunaan CPU, memori dan jaringan sehingga identifikasi bottleneck (apakah di Locust atau di aplikasi yang diuji) bisa lebih mudah dilakukan.
Walaupun nilai RPS di hasil pengujian lokal tidak memilih nilai yang berarti, saya tetap bisa menggunakan grafis di atas sebagai baseline bila saya melakukan perubahan pada aplikasi. Sebagai contoh, bagaimana bila saya mengubah database MongoDB yang dipakai menjadi MySQL Server? Walaupun terlihat sederhana, ini melibatkan cukup banyak perubahan karena driver JDBC masih melakukan blocking pada thread sehingga saya tidak bisa memakai Spring WebFlux. Pada saat memakai reactive stream di WebFlux, bila proses penulisan ke MongoDB gagal, operator berikutnya yang mempublikasikan event tidak akan dikerjakan. Tetapi saat kembali ke cara “lama”, untuk memastikan event dipublikasikan hanya setelah proses commit berhasil, saya harus menggunakan TransactionalEventListener. Selain itu, saya juga perlu mendefinisikan schema dengan FlyWay. Ini adalah hasil pengujian yang saya peroleh terlihat saat menjalankan Locust kembali:
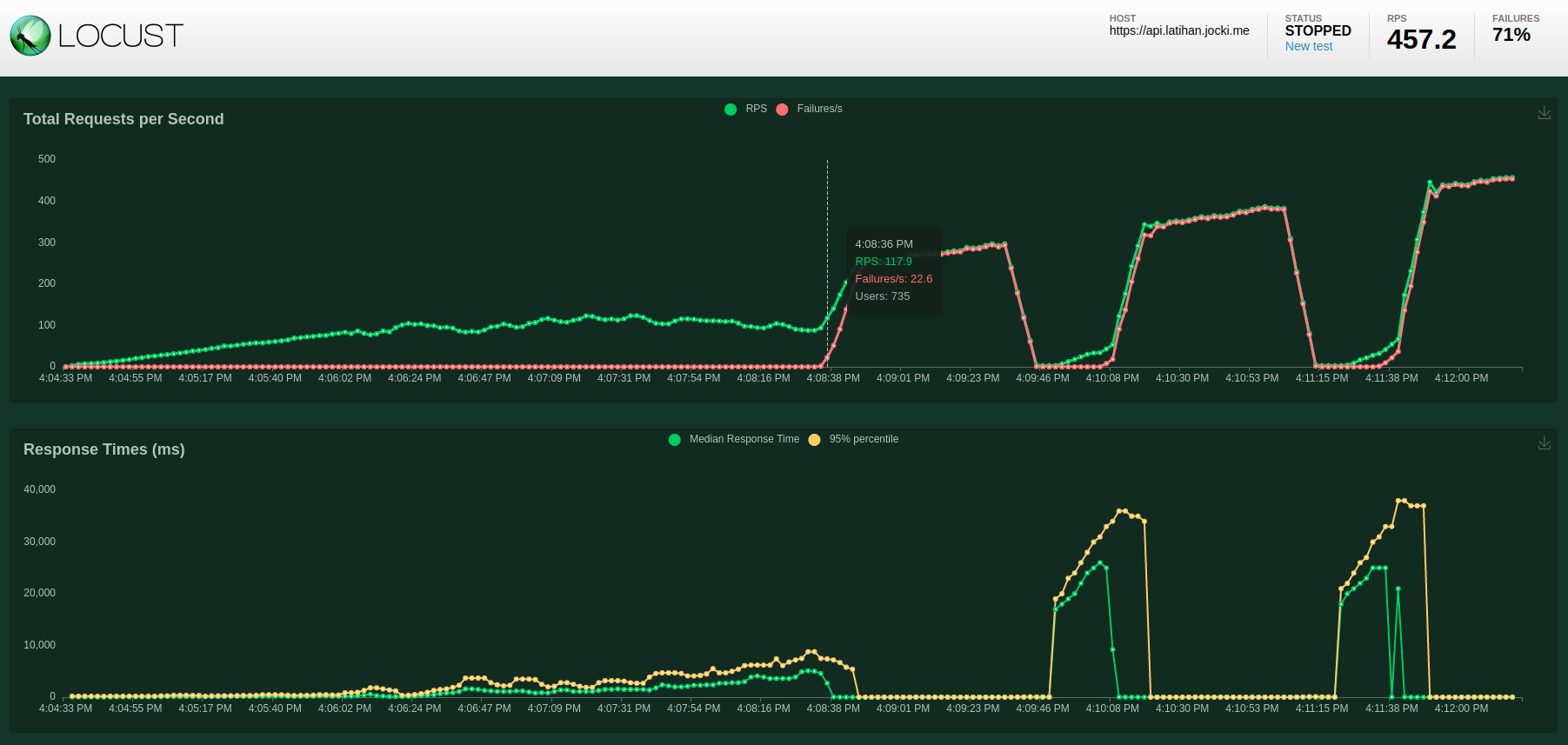
Setelah mencapai sekitar 735 pengguna, tiba-tiba pod untuk Spring Boot menjadi tidak responsif. Setelah di-restart oleh Kubernetes, tidak lama kemudian pod menjadi tidak responsif lagi. Saya menemukan banyak pesan kesalahan NullPointerException di log aplikasi tersebut. Bila dibandingkan dengan versi sebelumnya, pengalaman ini lebih buruk karena bottleneck-nya di aplikasi Spring Boot yang sampai crash dengan kesalahan yang sebelumnya tidak ada.